
Original Post: 2013/09/30 on the (no longer running) Cloud Party Blog. Some notes added in-line while re-posting.
Goals, Background, and Requirements
At Cloud Party (repost note: no longer running after we were acquired by the Yahoo Games team), we have built a platform for users to create, discover, and share massive amounts of 3D content in a multi-user, social environment. When I was starting to configure our live servers, we needed a front-end load balancer (or “reverse proxy”) setup which met a lot of requirements:
- WebSocket Support – our application relies heavily on WebSockets for all of its communication. A lot of solutions do not support WebSockets, especially back in 2012 when we were initially setting this up.
- Secure – everything must be done over SSL (HTTPS).
- Single Domain, Single Port (443) – without this a lot of things, from corporate firewalls, to WebGL security “fixes”, fail to work. From the outside, our application must look like any other web application, just a single port on a single domain.
- Run on Amazon Web Services, the cloud provider we’re using.
- Scalable – we want to be able to have large numbers of users connected simultaneously, and should be able to easily increase capacity by adding more machines.
- Transparent – ideally our application should not need to know that its behind a load balancer, so that while developing we can connect directly to our application and have no behavior differences when code goes live.
Our application servers are all written in Node.js (http://www.nodejs.org), and it became quickly apparent (see results below) that handling SSL in Node.js was not a viable option. I figured the SSL termination, the act of decrypting a TLS-encrypted (HTTPS) stream into plain text (HTTP), should be handled by the load balancing layer and not our application servers, and ideally be distributed, not just on the instance running the load balancer. This also means keeping our SSL private keys out of our application servers, which is a good security practice.
One thing our architecture does not need is session “stickiness” in the load balancer. Stickiness means that all requests from a single user get routed to the same backend server. Because we use a single WebSocket connection (which is guaranteed to be established to only one server) for almost anything that happens in a user’s “session”, the load balancer can simply distribute all requests regardless of where they come from. This is especially important because it means the load balancer can, in theory, be in front of the SSL terminator, instead of behind it (where it would have access to things like cookies in a request to deal with stickiness).
Candidates for Comparison and Test Setup
With noticing how slow Node.js’s SSL implementation was, I decided to profile a number of solutions and servers that supported SSL, specifically focusing on ones that could, in theory, also support WebSockets.
For the purpose of these speed tests, I launched two “m1.large” instances on AWS, one to serve as the server, and the other to run AB (Apache’s benchmarking tool) against it, and installed and configured the various servers, as well as set up a Node.js server serving files in a number of ways. All of the installation instructions, example apps, and configuration files are available on GitHub at https://github.com/Jimbly/node-https-websocket-loadbalance-test.
The following varieties of server software were compared:
- Trivial Node.js server – just the “Hello, world” example, shows theoretical maximum speed for Node.js handling requests
- Node.js Express server – using the popular Express framework to serve files (note that it is recommended to use a static caching server in front of Express for optimal performance)
- Custom Node.js caching file server – this effectively imitates our servers, which are generally serving any static content from in-memory caches
- Nginx – high performance HTTP server and reverse proxy. During my initial tests, this only supported WebSockets in raw mode with some source modifications, but supports WebSockets just fine now. For the performance tests, I just tested it serving static files, but it can be configured as a reverse proxy.
- Apache – standard popular HTTP server (just for comparison, not useful for us as a front end).
- Stud – SSL terminator. Not a back-end server, so in my tests, I put this in front of our custom Node.js caching file server.
- HAProxy – reverse proxy with a lot of options and support for WebSockets. Also not a back-end server, so in my tests I put this in front of our custom Node.js caching file server.
- HAProxy+stud – HAProxy as the front end, then going through stud for SSL termination, and then going to our custom Node.js caching file server.
For these tests, I set up all of the servers to serve a folder with 4 assets, of varying sizes, from Cloud Party – some mesh data, a thumbnail image, and a raw texture – as well as a simple WebSocket test HTML app (which was also used to ensure WebSockets were working through stud and HAProxy). I then ran ab (ApacheBench) to fetch each of the files 5000 times each, and recorded how long it took for each asset, as well as the total amount of CPU time consumed on the server. These two numbers are obviously closely related, but the first gives a better indication of how quickly individual requests can be handled, and the second gives a better indication of how much total performance the system can do. Especially when multiple processes on different machines will be involved, looking at the total CPU usage (and on which of the machines that CPU usage would be occurring) is a good way to determine how scalable a system is, and how powerful of machines are needed for each part of the system.
These tests are not perfect, because in reality there would be quite a few more servers around (at least, the load balancer front end would be on a different instance than the back end servers), so they ignore things like network latency (which should, in theory, affect all final setups in an identical fashion), but do a fairly good job of comparing the raw performance impact.
Test Results
Note: these results are shown in milliseconds per request instead of the more commonly used requests/second because the latter (similar to frames per second in graphics performance) can provide misleading information. For example, if a process is taking 5ms per request, and we can make two independant changes, each of which will reduce the time by 1ms, those changes are (clearly) each having the same amount of effect on performance, bringing us to 4ms/request and then 3ms/request. If quoting requests per second, then initially we have 200 requests/second, the first change brings us to 250 requests/second, and the second change brings us to 333 requests/second, which, erroneously, leads people to think the second change had a larger impact than the first.
Of the files tested, all of the smallish files (12B to 29KB) had virtually the same results (really just measuring request overhead, which is a good measure for us since we often do lots of small requests as we stream in a scene), so in the graphs below I will just analyze the results from one small file (2.2KB index.html) and one large file (768KB texture file).
Raw test results log from the tests are available at https://raw.github.com/Jimbly/node-https-websocket-loadbalance-test/master/tester/results.txt and the spreadsheet to make these graphics is avaiable at https://docs.google.com/spreadsheet/ccc?key=0Ak08vbmbPYzHdDlFSFlpMlRXZWJiTERpZk1zYjMwV1E&usp=sharing if you want to crunch some numbers.

This test shows us a few things that should not be surprising. Nginx and Apache are very good at serving static files. Node.js has a reasonable amount of overhead (note in the “node simple” case we’re not even serving files, just responding with “Hello, world”), but an efficient Node.js server is only a little slower than its theoretical max speed. Express, however, is not efficient at serving static files, but that is expected. If your site has a lot of static files, then it makes sense to put something in front of a Node.js server to handle the static requests, as even the most efficient Node.js server will not compare to a dedicated system for this. In Cloud Party’s case, all of our content is, at some level, dynamic, so we’re not particularly concerned with this extra overhead. Additionally, compared to the overhead for SSL (below), the difference of roughly 0.2ms/request is pretty small.
An (irrelevantly small) oddity I cannot explain shows up here (and later): HAProxy in front of our Node.js caching file server is measurably more efficient than just the Node.js caching file server. If HAProxy was doing some connection pooling/reuse, this might explain that, but, as far as I know, it is not doing such a thing. It’s possible Node.js is doing something much more efficient on a loop-back connection that it does not do on an external connection, or something like that.

For the large files, the times were all identical, indicating the bottleneck in all cases was not the server software, it was either the testing application or the network layer (the same number of bytes will have been transferred in all test cases). This is not unexpected, as serving a large raw stream of data should not be bottlenecked on anything other than the network layer.

Looking at the total CPU time (for handling all 25000 requests on each server) confirms most of the previous conclusions, though once again we see the puzzling bit of data showing the CPU time of the Node.js process is measurably less when HAProxy is in front of it than when it’s connected to directly.
Now we have some non-SSL baselines for comparison, on to the questions we really want answered: How slow is this SSL stuff, and how can we do it most efficiently?

Here we see some pretty drastic differences, some of which surprised me. All tests are orders of magnitude slower than the non-SSL case (non-SSL Nginx included for comparison). We are really just measuring the time to do an SSL handshake on a new connection here. Apache and Node.js are a clear losers, both of which take quite a bit more time than any of the others. Stud is a clear winner, taking 60% of the time (0.73ms less) Nginx takes per request, despite the fact that Stud is also forwarding to our (slower by 0.34ms, see above) Node.js back-end server. HAProxy combined with Stud and our Node.js still outperforms Nginx, so in this case that is a clear winner for a viable production solution. At the time I initially did these comparisons, Nginx did not reasonably support WebSockets, so I was unable to set up an identical test for Nginx forwarding to our Node.js backend, but judging from the performance difference between non-SSL Nginx and SSL Nginx, it is unlikely that it would get much better results.
Important note: If a server is configured to support it, usually an HTTPS client (a web browser) will re-use existing sockets, and only need to do the handshake once; so while these results are accurate for a single request, a bunch of small requests over a reused socket will be notably more efficient (probably comparable to the large tile test below).

Here we see the SSL requests taking only about twice as much time as the non-SSL version, and we appear to be no longer externally bottlenecked, but are now presumably seeing the difference in speed when actually encrypting a stream of data. Here Node.js is again a clear loser, and Stud+Node.js again is the fastest, with HAProxy+Stud+Node.js appearing to still be a winning combination.
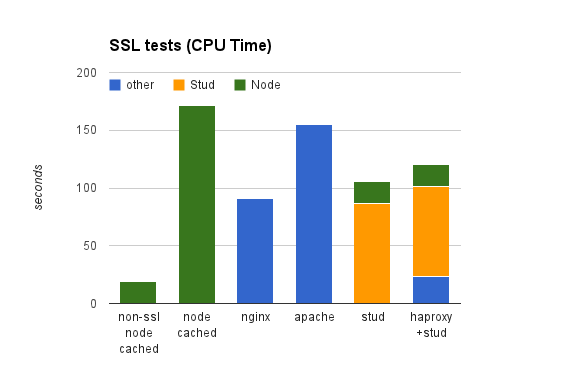
Looking at CPU usage, we get a clearer view of what’s going on. Here Stud and Nginx are seen both using roughly the same amount of CPU (plus the extra CPU the Node.js server takes to serve the files). The reasons Stud performs better in the ms/request test is that it is running on multiple cores so was able to handle the requests in a smaller amount of time. We also clearly see that HAProxy takes very little CPU, with most of the hard work being done by Stud. Because those are separate processes, possibly running on separate instances, this means we can have very low CPU usage per request on our load balancer instance and put the Stud processes on our distributed application instances, allowing for many more requests being handled by a single load balancer instance.
Final Conclusions
Based on our needs, and the results above, we went with a solution in which our load balancing instance is essentially running just HAProxy (in “tcp mode”, as it never decrypts the SSL stream), and each of our application instances are running a Stud process for each port (one port for each Node.js process which handles client requests – we usually run one process per core for these particular servers), and HAProxy load balances between all of the Stud processes on various instances. Due almost entirely to distributing the SSL termination workload, this solution means a single load balancer instance can handle significantly more requests per second than any of the other solutions. Also, since this workload is distributed to the same instances that are actually handling the individual requests, the load balancing may be a bit more even.

Initially, we are just running a single load balancer instance, as this will handle traffic corresponding to running tens if not hundreds of our backend servers, but at some point (we hope!) we will need more than one. At that point there are a number of things that can be done, the simplest of which is using DNS-level load balancing between a few instances, which then each load balance to all of the same backend instances.
Getting our load balancer configuration completely working, including all of the little details like reliable health checks, dealing with server downtime, and securely getting the client’s IP address down to the Node.js server, does involve a bit of work, and took some tinkering before I got everything working satisfactorily in production environment. But it has served us flawlessly since it was implemented, never having a failure. I hope to cover the details of our configuration and how you might actually set this up for your application in a future blog post, but you can find most of the options we used in the configuration files (although some of them are commented out, as they weren’t used in this test) in the GitHub repository linked to at the beginning of this post. For now, you can check it out in action by visiting Cloud Party! (repost note: no longer :,( )
Footnotes
On AWS, there is an Elastic Load Balancing (ELB) service which provides easy load balancing and SSL termination, but has some caveats. In HTTP/HTTPS mode, it does not support WebSockets, so that doesn’t work for our purposes. It does however, support a raw SSL/TCP mode, which allows for WebSockets to work, but has other caveats. ELB does not support load balancing out to multiple processes (ports) running on a single instance, so we would have to put another load balancer (such as HAProxy) on each instance to deal with a having only a single port exposed to the ELB. ELB also does not support any kind of stickiness in raw SSL/TCP mode, so if you need both stickiness and WebSockets, this won’t work for you, though as we mentioned earlier, our architecture does not require any kind of stickiness. Additionally, in raw SSL/TCP mode, at the time of doing our research, they provided no way for your application servers to get the original IP address of incoming requests (all IPs just register as the IP of the load balancer), which we felt was not acceptable, since using user’s IP address to track and deal with undesirable behavior is often an invaluable tool in managing an online community. However, Amazon appears to have recently added support for forwarding original IP addresses using the same protocol as HAProxy, so this may now be a viable alternative, since most of these other issues can be worked around without too much work.
Why is stud so much faster in the small file case? I’m not completely sure, but from reading about a bug I ran into in old versions of ApacheBench, I have a hunch that when Stud terminates an SSL connection, it simply terminates the underlying TCP connection (which is totally valid for HTTPS, and virtually instantaneous), whereas the other solutions follow the “correct” approach of doing a SSL handshake which “gracefully” terminates the connection. And, of course, by “correct” and “gracefully” I really mean “needless slow” and “wastefully”.
Misc repost notes:
- You may be interested in some related work at https://github.com/observing/balancerbattle
- HAProxy has support for SSL termination now, which makes for a simpler setup if you don’t want to distribute the SSL termination load, though I think you can do that with multiple HAProxy instances on various boxes. I’m not sure how HAProxy’s performance compares to stud’s.
- Node.js 0.11 reportedly has improved SSL/TLS speeds, that, if comparable, could allow Node.js to be a viable place for SSL termination, which would make things much simpler.
